Digital analytics, Soft skill, Google Analytics
Khám phá sự khác biệt về dữ liệu giữa Google Search Console và Analytics
15/09/2021 - Vy Hoang Cong Nhut
Mỗi công cụ thu thập, lưu trữ và giúp makerter phân tích data sẽ có những ưu nhược điểm riêng và phụ thuộc rất nhiều vào mô hình thiết kế của chúng. Hãy cùng MangoAds tìm hiểu kỹ hơn về 2 công cụ hỗ trợ đắc lực cho dân marketer này nhé!  Hình 1: Điều gì tạo nên sự khác biệt giữa Google Search Console và Analytics ? Khiếu nại phổ biến về Google Search Console (GSC) là dữ liệu không khớp với kết quả của Google Analytics. Ví dụ khi bạn thử tích hợp lưu lượng truy cập trang đích landing page traffic từ GA với lượt click chuột trong GCS thì lại không mang đến giá trị insight nào. Nếu dữ liệu từ 2 công cụ có thể kết nối với nhau, doanh nghiệp sẽ dễ dàng nhìn thấy bức tranh toàn cảnh hoạt động kinh doanh của mình. Nhưng tại sao Google lại không làm vậy?
Hình 1: Điều gì tạo nên sự khác biệt giữa Google Search Console và Analytics ? Khiếu nại phổ biến về Google Search Console (GSC) là dữ liệu không khớp với kết quả của Google Analytics. Ví dụ khi bạn thử tích hợp lưu lượng truy cập trang đích landing page traffic từ GA với lượt click chuột trong GCS thì lại không mang đến giá trị insight nào. Nếu dữ liệu từ 2 công cụ có thể kết nối với nhau, doanh nghiệp sẽ dễ dàng nhìn thấy bức tranh toàn cảnh hoạt động kinh doanh của mình. Nhưng tại sao Google lại không làm vậy?
Mục đích của Google Search Console và Google Analytics khác nhau
 Hình 2: Hai công cụ hướng tới hai mục đích khác nhau Giải thích ngắn gọn là hai nguồn dữ liệu có phương pháp đo lường khác nhau. GSC được xây dựng từ các cụm từ tìm kiếm (truy vấn), lượt click, selection (sự lựa chọn), log (nhật ký truy cập từ người dùng). Vì vậy dữ liệu sẽ hơi giống với các file nhật ký truy cập access log thường được marketer phân tích. Ngược lại, GA thu thập dữ liệu từ dòng click chuột clickstream qua các đoạn mã JavaScript. Để hiểu rõ hơn nguyên nhân gây ra sự khác biệt về dữ liệu giữa GSC và GA, trước tiên bạn cần hiểu cách mỗi công cụ thu thập và hiểu dữ liệu hành vi của người dùng.
Hình 2: Hai công cụ hướng tới hai mục đích khác nhau Giải thích ngắn gọn là hai nguồn dữ liệu có phương pháp đo lường khác nhau. GSC được xây dựng từ các cụm từ tìm kiếm (truy vấn), lượt click, selection (sự lựa chọn), log (nhật ký truy cập từ người dùng). Vì vậy dữ liệu sẽ hơi giống với các file nhật ký truy cập access log thường được marketer phân tích. Ngược lại, GA thu thập dữ liệu từ dòng click chuột clickstream qua các đoạn mã JavaScript. Để hiểu rõ hơn nguyên nhân gây ra sự khác biệt về dữ liệu giữa GSC và GA, trước tiên bạn cần hiểu cách mỗi công cụ thu thập và hiểu dữ liệu hành vi của người dùng.
Tìm hiểu nhật ký truy vấn và nhật ký nhấp chuột của người dùng
Mục đích Google luôn hướng tới là nâng cao chất lượng kết quả tìm kiếm tự nhiên bằng cách theo dõi các điểm dữ liệu data point ở từng lượt tìm kiếm của người dùng. Từ đó, Google mong muốn có cái nhìn toàn diện về những gì đang diễn ra trên giao diện hiển thị kết quả tìm kiếm SERPs.  Hình 3: Mục đích Google luôn hướng tới là nâng cao chất lượng kết quả tìm kiếm tự nhiên Dù nhiều lần Google nhấn mạnh không cho phép sử dụng lượt nhấp chuột và tỷ lệ nhấp chuột CTR ảnh hưởng tới thứ hạng Google, nhưng có nhiều bằng chứng cho thấy họ đang sử dụng dữ liệu nhấp chuột để đánh giá hiệu suất thứ hạng. Đây cũng là mâu thuẫn giữa Google và các SEOer.
Hình 3: Mục đích Google luôn hướng tới là nâng cao chất lượng kết quả tìm kiếm tự nhiên Dù nhiều lần Google nhấn mạnh không cho phép sử dụng lượt nhấp chuột và tỷ lệ nhấp chuột CTR ảnh hưởng tới thứ hạng Google, nhưng có nhiều bằng chứng cho thấy họ đang sử dụng dữ liệu nhấp chuột để đánh giá hiệu suất thứ hạng. Đây cũng là mâu thuẫn giữa Google và các SEOer.  Hình 4: Bằng chứng cho thấy Google sử dụng lượt nhấp để đánh giá thứ hạng Dưới đây là một số chỉ tiêu đo lường, đánh giá tiêu chuẩn để truy xuất thông tin:
Hình 4: Bằng chứng cho thấy Google sử dụng lượt nhấp để đánh giá thứ hạng Dưới đây là một số chỉ tiêu đo lường, đánh giá tiêu chuẩn để truy xuất thông tin:
- Lượt nhấp chuột
- Lượt bỏ qua kết quả hiển thị trên giao diện tìm kiếm SERP
- Tỷ lệ phiên thành công (session success rate)
- v.v.
Từ đây có thể thấy Google có mô hình riêng đo lường số lần click chuột, sự chú ý và độ hài lòng của người dùng. (Đọc thêm giải thích chi tiết của Bill Slawski về những mô hình này nhé) Mô hình này cũng được thảo luận trong một báo cáo tạm dịch là “Tích hợp lượt Click, độ thu hút và hài lòng vào mô hình đánh giá kết quả hiển thị trên giao diện tìm kiếm SERP” kết hợp với phương pháp dựa trên lượt click trong Xếp hạng theo thời gian Time-based ranking cho thấy rằng ai đó ít nhất đã dành thời gian để suy nghĩ về cách nhấp chuột có thể ảnh hưởng đến thứ hạng tìm kiếm trên Google. Theo Eric Schmidt vào năm 2011, Google đã thực hiện “13.111 đánh giá độ chính xác”, tức là trung bình khoảng 35 lượt đánh giá/ngày. Vì vậy nếu bạn đánh giá chất lượng tìm kiếm trong lĩnh vực sáng tạo nội dung như đội ngũ Google nghiên cứu hành vi search của người dùng, thì lượt click chuột luôn có khả năng ảnh hưởng đến xếp hạng của doanh nghiệp. Nhận định được tạm dịch dưới đây chứng minh cho sự thay đổi xếp hạng kết quả tìm kiếm dựa trên dữ liệu về nhật ký tìm kiếm và cách nó dự báo thứ hạng trong tương lai: “Thông tin được lưu trữ trong các nhật ký phiên truy cập session log 2060 hoặc nhật ký tìm kiếm search log có thể được công cụ sửa đổi thứ hạng modifier engine 2070 sử dụng để ảnh hưởng đến công cụ xếp hạng website/từ khóa ranking engine 2070. Nhìn chung, một lượng lớn thông tin từ dữ liệu tìm kiếm có thể được thu thập và sử dụng, khai thác để dự báo những nhu cầu tìm kiếm có thể có của người dùng trong tương lai. Do đó, lựa chọn click và xem một hoặc nhiều nội dung thông qua hành động search và tương tác với các kết quả hiển thị trên giao diện tìm kiếm có thể giúp cải thiện thứ hạng từ khóa về sau này.” Bên cạnh việc mang đến insight giá trị về tìm kiếm, cũng có rất nhiều dữ liệu nhiễu tạo ra bởi người dùng. Vậy nên marketer nên lấy dữ liệu có chọn lọc, để không lẫn các dữ liệu ảo.  Hình 5: Phát hiện dữ liệu ảo trong nhật ký truy vấn Vậy nhiễu dữ liệu là gì? Thử quan sát một cụm từ tìm kiếm truy vấn nhất định và trả lời các câu hỏi sau:
Hình 5: Phát hiện dữ liệu ảo trong nhật ký truy vấn Vậy nhiễu dữ liệu là gì? Thử quan sát một cụm từ tìm kiếm truy vấn nhất định và trả lời các câu hỏi sau:
- Bao nhiêu lần website của bạn hiển thị trên giao diện kết quả thứ hạng tìm kiếm?
- Bao nhiêu lần khách hàng click vào link ở phần tự động đề xuất autosuggest, sau đó công cụ tìm kiếm tự kích hoạt tính năng “fan” cho website thay vì đánh giá lần truy cập khách quan trên độ hài lòng thực tế?
- Số lần user vô tình lướt và click vào kết quả ngoài ý muốn?
Đây là một vài ví dụ về các dữ liệu Google thu thập nhưng không có giá trị tham khảo cao.
Có gì trong các file nhật ký ?
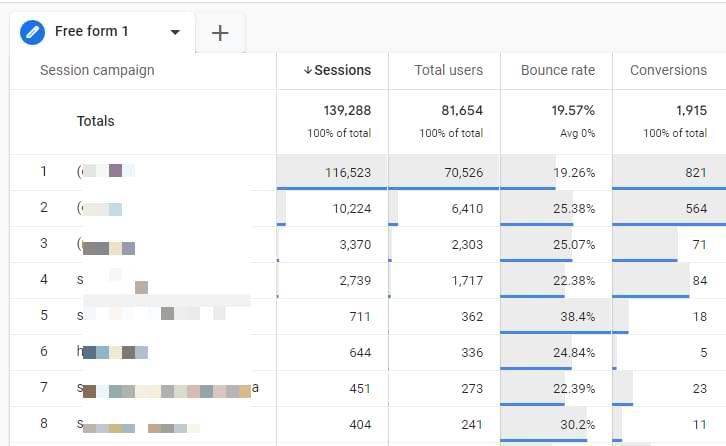
Nếu tài liệu về Google Search Appliance không còn được sử dụng, những nhật ký truy vấn và click chỉ đơn giản là các file văn bản lưu trữ dữ liệu về người dùng user và lịch sử tương tác với SERP. Tài liệu về nhật ký tìm kiếm có thể giống hoặc khác với nhật ký truy vấn và click chuột theo bằng sáng chế của Google (Google’s patents). Mặc dù dữ liệu trong hệ thống nhật ký được lưu trữ đơn giản nhưng chúng thể hiện rõ hơn về tiêu chí được theo dõi như thông tin user, truy vấn và hành vi click chuột. Nếu tìm hiểu sâu hơn, ta thấy trong hệ thống của Google và các phương pháp tạo thống kê từ bằng sáng chế có ghi lại nhật ký truy vấn của công cụ tìm kiếm. Từ đó, hệ thống sẽ cung cấp dữ liệu cho công cụ như Google Xu hướng - Google Trend vận hành. Trong một cuộc thảo luận khác, giả định có một tập dữ liệu chung được sử dụng cho cả Google Search Console và Google Ads Keyword Planner. Lúc này nhật ký truy vấn vận hành như sau: “Một công cụ tìm kiếm search engine có thể nhận được hàng triệu lượt truy vấn trong một ngày từ nhiều user trên thế giới. Với mỗi truy vấn, công cụ tìm kiếm tạo ra một bản ghi record truy vấn trong nhật ký truy vấn. Bản ghi truy vấn có thể gồm một hay nhiều cụm từ truy vấn, mốc thời gian cho biết khi nào search engine nhận được truy vấn, địa chỉ IP từ một thiết bị điện tử và mã xác định người dùng user identifier của truy vấn đó (thường từ web cookies)” Nói cách khác, tác giả muốn chứng minh nhật ký truy vấn của công cụ tìm kiếm có phần nhỉnh hơn so với Google search console. Tác giả cũng tiếp tục thảo luận về cookies, thiết bị điện tử dùng để truy vấn, ngôn ngữ user sử dụng và địa điểm thực hiện truy vấn được ghi lại. Họ cũng cung cấp hình sau để trình bày trực quan dữ liệu được thu thập trong nhật ký truy vấn:  Hình 6: Dữ liệu được trực quan hóa trong nhật ký truy vấn Mặt khác, bằng sáng chế đề cập đến khái niệm bản ghi của phiên truy cập giúp xác định xem một user đã thực hiện các tìm kiếm giống nhau hoặc tương tự trong khoảng thời gian nhất định. Yếu tố này đặc biệt quan trọng trong đo lường, báo cáo số lần hiển thị impression hoặc khối lượng tìm kiếm search volume: “Bản ghi phiên truy vấn bao gồm các truy vấn được search cùng thời điểm hoặc của người dùng có cùng sở thích. Theo một số phương án, quy trình trích xuất phiên truy vấn dựa trên phương pháp phỏng đoán. Ví dụ: các truy vấn liên tiếp sẽ được dự đoán thuộc cùng một phiên nếu chúng tương tự nhau ở một số cụm từ truy vấn hoặc cùng được gửi trong một khoảng thời gian xác định trước (ví dụ: mười phút) dù không có thuật ngữ truy vấn chung nào giữa chúng.” Các phương pháp heuristics hay “quy tắc của ngón cái” được đề cập ở trên có lẽ là cốt lõi tại sao Search Console và Google Analytics không bao giờ khớp với nhau. Về cơ bản, trong nhật ký truy vấn được ghi lại, Google sẽ xác định xem tính khác biệt giữa các tìm kiếm trong cùng một phiên truy cập. Do đó, bạn có thể hiểu là 2 lượt truy cập vào website khác nhau về từ khóa và trang đích landing page vẫn có thể được xem là 1 lượt hiển thị impression trong website dựa trên cách Google xác định lượt truy cập đó trong nhật ký truy vấn.
Hình 6: Dữ liệu được trực quan hóa trong nhật ký truy vấn Mặt khác, bằng sáng chế đề cập đến khái niệm bản ghi của phiên truy cập giúp xác định xem một user đã thực hiện các tìm kiếm giống nhau hoặc tương tự trong khoảng thời gian nhất định. Yếu tố này đặc biệt quan trọng trong đo lường, báo cáo số lần hiển thị impression hoặc khối lượng tìm kiếm search volume: “Bản ghi phiên truy vấn bao gồm các truy vấn được search cùng thời điểm hoặc của người dùng có cùng sở thích. Theo một số phương án, quy trình trích xuất phiên truy vấn dựa trên phương pháp phỏng đoán. Ví dụ: các truy vấn liên tiếp sẽ được dự đoán thuộc cùng một phiên nếu chúng tương tự nhau ở một số cụm từ truy vấn hoặc cùng được gửi trong một khoảng thời gian xác định trước (ví dụ: mười phút) dù không có thuật ngữ truy vấn chung nào giữa chúng.” Các phương pháp heuristics hay “quy tắc của ngón cái” được đề cập ở trên có lẽ là cốt lõi tại sao Search Console và Google Analytics không bao giờ khớp với nhau. Về cơ bản, trong nhật ký truy vấn được ghi lại, Google sẽ xác định xem tính khác biệt giữa các tìm kiếm trong cùng một phiên truy cập. Do đó, bạn có thể hiểu là 2 lượt truy cập vào website khác nhau về từ khóa và trang đích landing page vẫn có thể được xem là 1 lượt hiển thị impression trong website dựa trên cách Google xác định lượt truy cập đó trong nhật ký truy vấn.  Hình 7: Hai lượt truy cập có thể tính là 1 lần hiển thị theo cơ chế của Google Mặt khác, nhật ký nhấp chuột sẽ ghi lại dữ liệu hành vi tìm kiếm của người dùng một khi họ nhấn vào các kết quả search. Bằng sáng chế về Xếp hạng kết quả tìm kiếm sửa đổi dựa trên thống kê dữ liệu tìm kiếm cho ta thấy dữ liệu nào có thể được lưu trữ trong tập dữ liệu này (tôi nhấn mạnh): “Thông tin bao gồm các kết quả hiển thị được click vào, có thể được lưu trữ trong (các) nhật ký phiên session log 2060. Mặc khác, dữ liệu tìm kiếm và lịch sử kết quả click chuột ũng có thể được lưu trong nhật ký tìm kiếm search log. Nhìn chung, thông tin được ghi lại trong nhật ký (với mỗi sự lựa chọn của người dùng user selection) thường gồm: cụm từ truy vấn (Q), tài liệu (D), thời gian (T) giữa hai lựa chọn liên tiếp của kết quả tìm kiếm, ngôn ngữ (L) được sử dụng bởi người dùng và quốc gia (C) nơi người dùng có thể đang ở (ví dụ: dựa trên máy chủ được sử dụng để truy cập hệ thống IR). Trong một số triển khai khác, người ta thường ghi lại thông tin khác liên quan đến tương tác của người dùng với thứ hạng website trên search engine như thông tin tiêu cực (ví dụ như các kết quả không được click vào), vị trí user click chuột, điểm IR của kết quả được click, điểm IR của kết quả có hạng cao hơn kết quả được click, tiêu đề và đoạn trích nổi bật được hiển thị trong lần truy vấn đó, cookie của người dùng, tuổi cookie cookie age, địa chỉ IP (Giao thức Internet), tác nhân người dùng user agent của trình duyệt, v.v. Thông tin được ghi lại khác như các kết quả tìm kiếm được trả về cho một truy vấn, trong đó kết quả tìm kiếm là các mục nội dung được phân loại trong kho tài liệu khác nhau. Một cách khác là các thông tin tương tự về điểm IR, vị trí truy cập, v.v.được ghi lại chung cho một phiên hoặc nhiều phiên của người dùng. Ở trường hợp khác, việc ghi lại thông tin tương tự trên không được liên kết với phiên người dùng hoặc có thể được ghi lại cho mỗi lần nhấp trước và sau lần nhấp hiện tại ” Từ đây có thể thấy công cụ Google Search Console thể hiện rõ ràng những hạn chế khi xây dựng giao diện người dùng dựa trên tập dữ liệu thử nghiệm, còn Google Search Console chi mô tả được một phần nhỏ thông tin từ tập dữ liệu này. Qua đây ta cũng hiểu hơn về cơ chế hoạt động của một giao diện hiển thị kết quả tìm kiếm SERP. Ngoài ra, không chỉ có các lần nhấp chuột được theo dõi, các tính năng đằng sau cũng giúp xác định vị trí thứ hạng của một kết quả trong SERP.
Hình 7: Hai lượt truy cập có thể tính là 1 lần hiển thị theo cơ chế của Google Mặt khác, nhật ký nhấp chuột sẽ ghi lại dữ liệu hành vi tìm kiếm của người dùng một khi họ nhấn vào các kết quả search. Bằng sáng chế về Xếp hạng kết quả tìm kiếm sửa đổi dựa trên thống kê dữ liệu tìm kiếm cho ta thấy dữ liệu nào có thể được lưu trữ trong tập dữ liệu này (tôi nhấn mạnh): “Thông tin bao gồm các kết quả hiển thị được click vào, có thể được lưu trữ trong (các) nhật ký phiên session log 2060. Mặc khác, dữ liệu tìm kiếm và lịch sử kết quả click chuột ũng có thể được lưu trong nhật ký tìm kiếm search log. Nhìn chung, thông tin được ghi lại trong nhật ký (với mỗi sự lựa chọn của người dùng user selection) thường gồm: cụm từ truy vấn (Q), tài liệu (D), thời gian (T) giữa hai lựa chọn liên tiếp của kết quả tìm kiếm, ngôn ngữ (L) được sử dụng bởi người dùng và quốc gia (C) nơi người dùng có thể đang ở (ví dụ: dựa trên máy chủ được sử dụng để truy cập hệ thống IR). Trong một số triển khai khác, người ta thường ghi lại thông tin khác liên quan đến tương tác của người dùng với thứ hạng website trên search engine như thông tin tiêu cực (ví dụ như các kết quả không được click vào), vị trí user click chuột, điểm IR của kết quả được click, điểm IR của kết quả có hạng cao hơn kết quả được click, tiêu đề và đoạn trích nổi bật được hiển thị trong lần truy vấn đó, cookie của người dùng, tuổi cookie cookie age, địa chỉ IP (Giao thức Internet), tác nhân người dùng user agent của trình duyệt, v.v. Thông tin được ghi lại khác như các kết quả tìm kiếm được trả về cho một truy vấn, trong đó kết quả tìm kiếm là các mục nội dung được phân loại trong kho tài liệu khác nhau. Một cách khác là các thông tin tương tự về điểm IR, vị trí truy cập, v.v.được ghi lại chung cho một phiên hoặc nhiều phiên của người dùng. Ở trường hợp khác, việc ghi lại thông tin tương tự trên không được liên kết với phiên người dùng hoặc có thể được ghi lại cho mỗi lần nhấp trước và sau lần nhấp hiện tại ” Từ đây có thể thấy công cụ Google Search Console thể hiện rõ ràng những hạn chế khi xây dựng giao diện người dùng dựa trên tập dữ liệu thử nghiệm, còn Google Search Console chi mô tả được một phần nhỏ thông tin từ tập dữ liệu này. Qua đây ta cũng hiểu hơn về cơ chế hoạt động của một giao diện hiển thị kết quả tìm kiếm SERP. Ngoài ra, không chỉ có các lần nhấp chuột được theo dõi, các tính năng đằng sau cũng giúp xác định vị trí thứ hạng của một kết quả trong SERP.
Như thế nào là lượt click của người dùng ?
 Hình 8: Lượt click của người dùng được thống kê và theo dõi mỗi ngày Theo tài liệu Google Search Appliance, ta không thể định nghĩa rõ một click hay impression. Chẳng hạn khi bạn search một từ khóa và click vào kết quả search, sau đó quay lại trang kết quả và click vào kết quả đó 1 lần nữa. Vậy đây được xem là 2 lượt click hay 1 ? Tuy nhiên, ta có thể tìm ra câu trả lời trong Hệ thống và phương pháp tạo thống kê từ Bằng sáng chế Nhật ký truy vấn của công cụ tìm kiếm. Dữ liệu được mô phỏng trong tài liệu này thường là một tập dữ liệu mẫu, rất có ý nghĩa với công cụ Google Trend. Ngoài ra có một số trường hợp không lấy mẫu dữ liệu: “Để lấy được thông tin đáng tin cậy từ nhật ký truy cập 108, bạn không cần phải lần lượt xem qua tất cả bản ghi truy vấn (còn gọi là bản ghi nhật ký log record hoặc bản ghi giao dịch transaction record) trong nhật ký truy vấn. Miễn là thông tin thống kê được lấy từ đủ số lượng mẫu trong nhật ký truy vấn, chúng cũng đáng tin cậy như thông tin thu được từ tất cả bản ghi nhật ký khác. Với cách này, bạn có thể tiết kiệm thời gian và tài nguyên máy tính khi khảo sát lấy mẫu dữ liệu. Do đó, quy trình lấy mẫu trong nhật ký truy vấn 110 có thể được sử dụng để chia thành các nhóm dữ liệu mẫu nhật ký truy vấn 108 với lượng mẫu ít hơn và tạo ra nhật ký truy vấn phụ 112 (sub-sampled query log) với lượng mẫu đó. Ví dụ: Nhật ký truy vấn lấy mẫu phụ có thể chứa 10% hoặc 20% các bản ghi nhật ký so với nhật ký ban đầu 108. Lưu ý rằng quá trình lấy mẫu là tùy chọn, người ta cũng có thể sử dụng toàn bộ bản ghi nhật ký truy vấn 108 để tạo thông tin thống kê.” Google cũng xem xét rằng hai truy vấn tương tự có thể đại diện cho 1 lượt tìm kiếm. Đây là điểm cốt lõi tạo nên sự khác biệt giữa các công cụ đo lường dữ liệu marketing của Google. Vậy nên gần đây, Google đã chuyển sang cung cấp phiên bản search volume số ít và số nhiều của từ khóa có cùng lượng tìm kiếm. Điều này đã làm nổi lên một cuộc thảo luận sôi nổi trong cộng đồng nghiên cứu về công cụ tìm kiếm. MangoAds sẽ trình bày toàn bộ cuộc thảo luận từ bằng sáng chế dưới đây: “Ví dụ người dùng search “Nhà hàng quận 1 tphcm” để tìm xem các địa điểm nhà hàng tại quận 1, TPHCM. Sau đó họ tiếp tục search thông tin nhà hàng quận 3, TPHCM. Hai truy vấn này có liên quan về mặt logic vì đều liên quan đến TPHCM và có thời gian gửi truy vấn cách nhau không quá xa” “[0035] Một số cách làm khác, các truy vấn có liên quan được nhóm lại với nhau thành 1 phiên truy vấn nhằm mô tả chính xác hơn hoạt động tìm kiếm của người dùng. Phiên truy vấn thường bao gồm một hoặc nhiều truy vấn từ một người dùng, cùng được gửi trong khoảng thời gian (khoảng 10 phút) hoặc có các cụm từ truy vấn trùng lặp với chênh lệch thời gian search có thể lớn một chút (khoảng 2 giờ). Truy vấn liên quan đến chủ đề, sở thích khác nhau được xếp vào các phiên khác nhau, trừ khi thời gian search giữa các truy vấn liên tiếp rất gần nhau. Cùng một người dùng đang tìm kiếm nhà hàng ở quận 1 có thể search về “iphone 12 chính hãng”. Do đó, cụm search về “nhà hàng quận 1 tphcm” sẽ không được xếp vào các truy vấn liên quan đến nhà hàng. Do đó, các truy vấn từ một người dùng có thể được liên kết với nhiều phiên. Hai phiên được liên kết với cùng 1 người sẽ chia sẻ cùng 1 cookie nhưng số nhận dạng phiên session identifier khác nhau.” Nhìn chung, Google sử dụng một loạt các phương pháp ghi nhận nhật ký đằng sau công cụ tìm kiếm để xác định riêng biệt thế nào là lượt search và lượt click. Tuy nhiên, nhận định này có thể hoặc không hợp với quan điểm hoặc nền tảng phân tích phiên truy cập của doanh nghiệp bạn.
Hình 8: Lượt click của người dùng được thống kê và theo dõi mỗi ngày Theo tài liệu Google Search Appliance, ta không thể định nghĩa rõ một click hay impression. Chẳng hạn khi bạn search một từ khóa và click vào kết quả search, sau đó quay lại trang kết quả và click vào kết quả đó 1 lần nữa. Vậy đây được xem là 2 lượt click hay 1 ? Tuy nhiên, ta có thể tìm ra câu trả lời trong Hệ thống và phương pháp tạo thống kê từ Bằng sáng chế Nhật ký truy vấn của công cụ tìm kiếm. Dữ liệu được mô phỏng trong tài liệu này thường là một tập dữ liệu mẫu, rất có ý nghĩa với công cụ Google Trend. Ngoài ra có một số trường hợp không lấy mẫu dữ liệu: “Để lấy được thông tin đáng tin cậy từ nhật ký truy cập 108, bạn không cần phải lần lượt xem qua tất cả bản ghi truy vấn (còn gọi là bản ghi nhật ký log record hoặc bản ghi giao dịch transaction record) trong nhật ký truy vấn. Miễn là thông tin thống kê được lấy từ đủ số lượng mẫu trong nhật ký truy vấn, chúng cũng đáng tin cậy như thông tin thu được từ tất cả bản ghi nhật ký khác. Với cách này, bạn có thể tiết kiệm thời gian và tài nguyên máy tính khi khảo sát lấy mẫu dữ liệu. Do đó, quy trình lấy mẫu trong nhật ký truy vấn 110 có thể được sử dụng để chia thành các nhóm dữ liệu mẫu nhật ký truy vấn 108 với lượng mẫu ít hơn và tạo ra nhật ký truy vấn phụ 112 (sub-sampled query log) với lượng mẫu đó. Ví dụ: Nhật ký truy vấn lấy mẫu phụ có thể chứa 10% hoặc 20% các bản ghi nhật ký so với nhật ký ban đầu 108. Lưu ý rằng quá trình lấy mẫu là tùy chọn, người ta cũng có thể sử dụng toàn bộ bản ghi nhật ký truy vấn 108 để tạo thông tin thống kê.” Google cũng xem xét rằng hai truy vấn tương tự có thể đại diện cho 1 lượt tìm kiếm. Đây là điểm cốt lõi tạo nên sự khác biệt giữa các công cụ đo lường dữ liệu marketing của Google. Vậy nên gần đây, Google đã chuyển sang cung cấp phiên bản search volume số ít và số nhiều của từ khóa có cùng lượng tìm kiếm. Điều này đã làm nổi lên một cuộc thảo luận sôi nổi trong cộng đồng nghiên cứu về công cụ tìm kiếm. MangoAds sẽ trình bày toàn bộ cuộc thảo luận từ bằng sáng chế dưới đây: “Ví dụ người dùng search “Nhà hàng quận 1 tphcm” để tìm xem các địa điểm nhà hàng tại quận 1, TPHCM. Sau đó họ tiếp tục search thông tin nhà hàng quận 3, TPHCM. Hai truy vấn này có liên quan về mặt logic vì đều liên quan đến TPHCM và có thời gian gửi truy vấn cách nhau không quá xa” “[0035] Một số cách làm khác, các truy vấn có liên quan được nhóm lại với nhau thành 1 phiên truy vấn nhằm mô tả chính xác hơn hoạt động tìm kiếm của người dùng. Phiên truy vấn thường bao gồm một hoặc nhiều truy vấn từ một người dùng, cùng được gửi trong khoảng thời gian (khoảng 10 phút) hoặc có các cụm từ truy vấn trùng lặp với chênh lệch thời gian search có thể lớn một chút (khoảng 2 giờ). Truy vấn liên quan đến chủ đề, sở thích khác nhau được xếp vào các phiên khác nhau, trừ khi thời gian search giữa các truy vấn liên tiếp rất gần nhau. Cùng một người dùng đang tìm kiếm nhà hàng ở quận 1 có thể search về “iphone 12 chính hãng”. Do đó, cụm search về “nhà hàng quận 1 tphcm” sẽ không được xếp vào các truy vấn liên quan đến nhà hàng. Do đó, các truy vấn từ một người dùng có thể được liên kết với nhiều phiên. Hai phiên được liên kết với cùng 1 người sẽ chia sẻ cùng 1 cookie nhưng số nhận dạng phiên session identifier khác nhau.” Nhìn chung, Google sử dụng một loạt các phương pháp ghi nhận nhật ký đằng sau công cụ tìm kiếm để xác định riêng biệt thế nào là lượt search và lượt click. Tuy nhiên, nhận định này có thể hoặc không hợp với quan điểm hoặc nền tảng phân tích phiên truy cập của doanh nghiệp bạn.
Cách Analytics xác định phiên
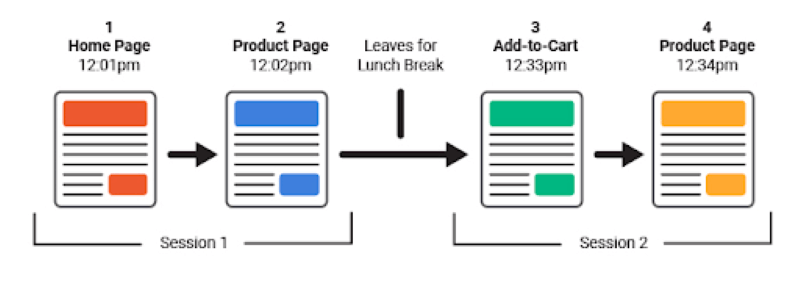 Hình 9: Phiên truy cập được xác định theo thời gian Các gói Analytics cũng tuân theo loạt các phương pháp đo lường người dùng và hoạt động của họ. Tùy thuộc vào từng gói Analytics, “phiên” hoặc một lượt truy cập được xác định bởi người dùng. Theo tài liệu Google Analytics, mặc định một phiên sẽ duy trì trong 30 phút nếu người dùng không có hành động mới, bạn có thể điều chỉnh thời gian kéo dài từ vài giây đến vài giờ. Tuy ta không thể biết chính xác một phiên của Google là bao nhiêu thời gian, nhưng căn cứ vào cách vận hành truy vấn đề cập ở trên, thời gian 1 phiên có thể ít hơn 30 phút. Trong bằng sáng chế liên quan đến Google Analytics là Hệ thống và phương pháp tổng hợp dữ liệu phân tích, tác giả nói về việc người dùng bị theo dõi qua ID phiên và cách vô hiệu hóa cơ chế đó: “ID phiên thường được cấp cho khách truy cập trong lần truy cập đầu tiên vào một trang web. Nó khác với ID người dùng ở chỗ các phiên thường tồn tại trong thời gian ngắn (được chủ website thiết lập từ vài giây đến vài giờ) khi khách truy cập không có hành động mới. Ngoài ra, ID phiên có thể hết hiệu lực sau khi đạt được một mục tiêu nhất định (ví dụ: khi người mua đã đã hoàn thành đơn đặt hàng của mình, anh ấy không thể sử dụng cùng một ID phiên để thêm nhiều mặt hàng hơn).” Do đó, người dùng có thể có nhiều phiên cho cùng một lượt truy cập. Các gói phân tích analytics package là công cụ khá phức tạp với nhiều mức độ thiết lập cấu hình khác nhau. Chính vì quá nhiều yếu tố về cá nhân hóa ảnh hưởng đến từng gói phân tích, nên sẽ không có sự nhất quán về tiêu chí đánh giá từng gói phân tích. Nói một cách mở rộng với 2 công cụ đo lường, chúng không có sự nhất quán trong cách sử dụng, thiết lập và cả dữ liệu.
Hình 9: Phiên truy cập được xác định theo thời gian Các gói Analytics cũng tuân theo loạt các phương pháp đo lường người dùng và hoạt động của họ. Tùy thuộc vào từng gói Analytics, “phiên” hoặc một lượt truy cập được xác định bởi người dùng. Theo tài liệu Google Analytics, mặc định một phiên sẽ duy trì trong 30 phút nếu người dùng không có hành động mới, bạn có thể điều chỉnh thời gian kéo dài từ vài giây đến vài giờ. Tuy ta không thể biết chính xác một phiên của Google là bao nhiêu thời gian, nhưng căn cứ vào cách vận hành truy vấn đề cập ở trên, thời gian 1 phiên có thể ít hơn 30 phút. Trong bằng sáng chế liên quan đến Google Analytics là Hệ thống và phương pháp tổng hợp dữ liệu phân tích, tác giả nói về việc người dùng bị theo dõi qua ID phiên và cách vô hiệu hóa cơ chế đó: “ID phiên thường được cấp cho khách truy cập trong lần truy cập đầu tiên vào một trang web. Nó khác với ID người dùng ở chỗ các phiên thường tồn tại trong thời gian ngắn (được chủ website thiết lập từ vài giây đến vài giờ) khi khách truy cập không có hành động mới. Ngoài ra, ID phiên có thể hết hiệu lực sau khi đạt được một mục tiêu nhất định (ví dụ: khi người mua đã đã hoàn thành đơn đặt hàng của mình, anh ấy không thể sử dụng cùng một ID phiên để thêm nhiều mặt hàng hơn).” Do đó, người dùng có thể có nhiều phiên cho cùng một lượt truy cập. Các gói phân tích analytics package là công cụ khá phức tạp với nhiều mức độ thiết lập cấu hình khác nhau. Chính vì quá nhiều yếu tố về cá nhân hóa ảnh hưởng đến từng gói phân tích, nên sẽ không có sự nhất quán về tiêu chí đánh giá từng gói phân tích. Nói một cách mở rộng với 2 công cụ đo lường, chúng không có sự nhất quán trong cách sử dụng, thiết lập và cả dữ liệu.
Tại sao không thể hợp nhất hai công cụ phân tích ?
Một cách đơn giản, một cú click chuột trên GSC không phải là 1 phiên trên GA và ngược lại. Trong trường hợp này, người dùng click 2 lần có thể hiểu là 2 lần click trong GSC và 1 phiên trong GA.  Hình 10: GSC hoàn toàn khác GA ở tính năng lẫn mục đích sử dụng Ngoài ra, nếu người dùng thực hiện hai tìm kiếm và hai lần nhấp khác nhau, hoạt động của họ có thể được coi là một lần hiển thị và một lần nhấp, từ đó cũng có thể vô hiệu hóa ID phiên của họ hoặc khi hết thời hạn phiên thì cũng được coi là hai lượt truy cập trong hai phiên riêng biệt Mặt khác, khi người dùng nhấp vào đường link website của bạn trên SERP, đôi khi các công cụ đo lường không hề được kích hoạt để theo dõi người dùng mà không vì nguyên nhân nào. Vì vậy, không phải lúc nào các công cụ phân tích cũng mang lại nguồn dữ liệu đáng tin cậy. Cuối cùng, GSC sử dụng URL chuẩn, trong khi công cụ phân tích GA có thể dùng bất kỳ URL nào để báo cáo về các phiên của người dùng. Google có nhắc về điều này trong tài liệu của họ. Tuy nhiên, họ chú trọng giải thích sự khác biệt trong bối cảnh tích hợp GSC với GA hơn là giải thích sự khác biệt trong phương pháp đo lường.
Hình 10: GSC hoàn toàn khác GA ở tính năng lẫn mục đích sử dụng Ngoài ra, nếu người dùng thực hiện hai tìm kiếm và hai lần nhấp khác nhau, hoạt động của họ có thể được coi là một lần hiển thị và một lần nhấp, từ đó cũng có thể vô hiệu hóa ID phiên của họ hoặc khi hết thời hạn phiên thì cũng được coi là hai lượt truy cập trong hai phiên riêng biệt Mặt khác, khi người dùng nhấp vào đường link website của bạn trên SERP, đôi khi các công cụ đo lường không hề được kích hoạt để theo dõi người dùng mà không vì nguyên nhân nào. Vì vậy, không phải lúc nào các công cụ phân tích cũng mang lại nguồn dữ liệu đáng tin cậy. Cuối cùng, GSC sử dụng URL chuẩn, trong khi công cụ phân tích GA có thể dùng bất kỳ URL nào để báo cáo về các phiên của người dùng. Google có nhắc về điều này trong tài liệu của họ. Tuy nhiên, họ chú trọng giải thích sự khác biệt trong bối cảnh tích hợp GSC với GA hơn là giải thích sự khác biệt trong phương pháp đo lường. 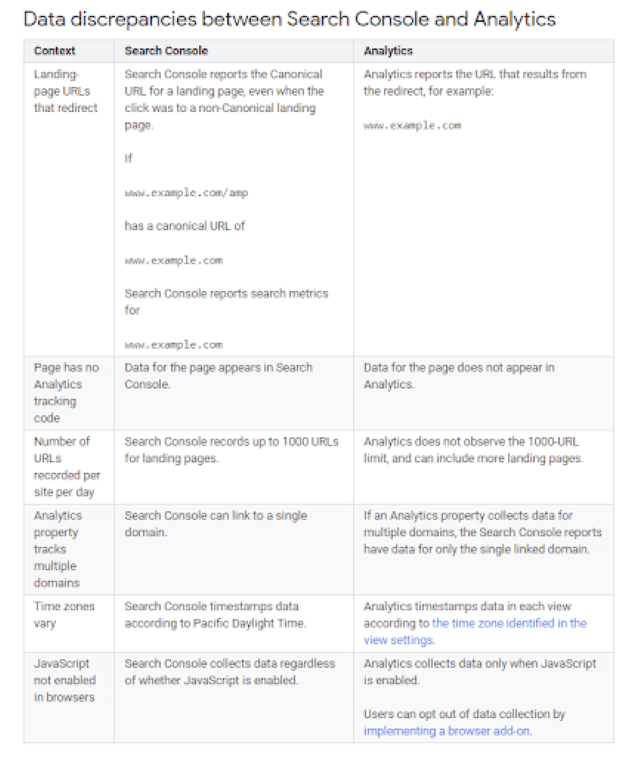 Hình 11: Điểm khác biệt của các công cụ khi tích hợp vào website
Hình 11: Điểm khác biệt của các công cụ khi tích hợp vào website
Vấn đề được đặt ra
Một vấn đề cốt lõi của nhiều marketer là họ không tin vào dữ liệu của GSC vì nghĩ GA là đo lường hiệu quả, sở hữu dữ liệu cơ bản và đầy đủ hơn. Việc cho rằng 2 công cụ là tương đương nhau và đem ra so sánh là không thực tế. Chúng ta đang chỉ nhìn 2 công cụ một cách phiến diện vì vai trò đo lường của chúng là khác nhau. Dữ liệu hiệu suất từ GSC là đo lường trên cả công cụ Google không phải chỉ trong phạm vi website của bạn. Ngoài ra, dữ liệu thứ hạng của GSC cũng khác với thứ hạng thực của doanh nghiệp.
Làm thế nào để có được nhiều dữ liệu chính xác hơn
Độ chính xác dữ liệu trong GSC sẽ tăng khi bạn thiết lập website của mình rõ hơn từ cấu trúc đến nội dung. Nói cách khác, nếu bạn phân lớp các trang, thư mục của website rõ ràng thì công cụ sẽ mang lại nhiều dữ liệu chính xác hơn. Việc này có thể mất nhiều thời gian để tìm hiểu và phân loại dữ liệu trong Google Search Console, nhưng gia tăng độ chính xác cũng hữu ích cho các chiến dịch marketing, A/B testing hay tìm kiếm những insight mang tính đột phá cho doanh nghiệp.  Hình 12: GSC ứng dụng cho việc thực hiện A/B testing Khi thêm nhiều thiết lập cấu hình mới, hãy nhớ GSC giới hạn doanh nghiệp ở mức 1000 truy vấn cho mỗi bộ lọc tìm kiếm search filter. Vì vậy bạn nên cân nhắc sử dụng API để lấy dữ liệu vì nó trả về 5000 cho mỗi bộ lọc tìm kiếm. Bên cạnh đó, để trích xuất càng nhiều dữ liệu càng tốt, bạn nên thử thiết lập vòng lặp thu thập dữ liệu cho từng đợt dữ liệu trong bộ lọc tìm kiếm (S/O cho William Sears). Nhờ vậy, bạn sẽ lấy được nhiều dữ liệu nhất có thể trong quá trình sử dụng bộ lọc. Thực hiện đồng thời các phương án trên theo danh mục website của bạn để lấy được dữ liệu chính xác nhất có thể.
Hình 12: GSC ứng dụng cho việc thực hiện A/B testing Khi thêm nhiều thiết lập cấu hình mới, hãy nhớ GSC giới hạn doanh nghiệp ở mức 1000 truy vấn cho mỗi bộ lọc tìm kiếm search filter. Vì vậy bạn nên cân nhắc sử dụng API để lấy dữ liệu vì nó trả về 5000 cho mỗi bộ lọc tìm kiếm. Bên cạnh đó, để trích xuất càng nhiều dữ liệu càng tốt, bạn nên thử thiết lập vòng lặp thu thập dữ liệu cho từng đợt dữ liệu trong bộ lọc tìm kiếm (S/O cho William Sears). Nhờ vậy, bạn sẽ lấy được nhiều dữ liệu nhất có thể trong quá trình sử dụng bộ lọc. Thực hiện đồng thời các phương án trên theo danh mục website của bạn để lấy được dữ liệu chính xác nhất có thể.
Mỗi công cụ đều có ưu nhược điểm riêng
 Hình 13: Mỗi công cụ có những mục đích riêng Các công cụ đo lường được giới thiệu vào cuối năm 2011, đã báo hiệu rằng dữ liệu tìm kiếm tự nhiên sẽ dần bị ảnh hưởng và ít dần hơn. Trên thực tế, một lượt truy cập sẽ không còn chỉ thuộc về 1 phiên truy cập. Dữ liệu của GSC có thể là nguồn dữ liệu tối ưu nhất doanh nghiệp nên sử dụng trong tương lai. Mặc dù dữ liệu này không phản ánh được quan điểm của bạn, không có nghĩa là nó không đúng. Cũng như bạn không thể so sánh dữ liệu của Facebook Ads với Google Analytics, nên cũng không thể nghĩ rằng Google Search Console sẽ khớp với dữ liệu của mình. Hy vọng MangoAds đã giúp bạn lý giải phần nào về sự khác biệt trong dữ liệu của Google Search Console và Google Analytics. Như vậy, mỗi công cụ đều có những tính năng riêng, tùy theo mục đích marketing, doanh nghiệp có thể sử dụng hiệu quả cả 2 công cụ này để phân tích data đem đến hiệu quả marketing tốt nhất!
Hình 13: Mỗi công cụ có những mục đích riêng Các công cụ đo lường được giới thiệu vào cuối năm 2011, đã báo hiệu rằng dữ liệu tìm kiếm tự nhiên sẽ dần bị ảnh hưởng và ít dần hơn. Trên thực tế, một lượt truy cập sẽ không còn chỉ thuộc về 1 phiên truy cập. Dữ liệu của GSC có thể là nguồn dữ liệu tối ưu nhất doanh nghiệp nên sử dụng trong tương lai. Mặc dù dữ liệu này không phản ánh được quan điểm của bạn, không có nghĩa là nó không đúng. Cũng như bạn không thể so sánh dữ liệu của Facebook Ads với Google Analytics, nên cũng không thể nghĩ rằng Google Search Console sẽ khớp với dữ liệu của mình. Hy vọng MangoAds đã giúp bạn lý giải phần nào về sự khác biệt trong dữ liệu của Google Search Console và Google Analytics. Như vậy, mỗi công cụ đều có những tính năng riêng, tùy theo mục đích marketing, doanh nghiệp có thể sử dụng hiệu quả cả 2 công cụ này để phân tích data đem đến hiệu quả marketing tốt nhất!

Mục lục
Bài viết liên quan